エージェントのプライベート化が進む時代において、OllamaはAIモデルを実行するための基盤として非常に適しています。ニーズに応じて異なるモデルを組み合わせて読み込むことで、エージェントの行動目的を実現できます。ただし、Ollamaの公式ライブラリに含まれるモデルは一般的に容量が大きく、カスタマイズもできません。それに比べ、HuggingFaceからモデルを取得するのは良い選択肢と言えます。

ちょうど最近、QwenとGemmaの両方が新しいモデルをリリースし、AgentやSkillとの相性が良いと謳っていたので、早速試してみることにした。しかし、最強とされるQwen3.5をロードしたにもかかわらず、動作はまるで独り言を呟く狂人のようだった。これはおそらくモデルの知能の問題ではなく、Ollamaのモデルファイルに「脳外科手術」が必要だったのだろう。

HuggingFaceから取得したモデルを使用する場合、自身のニーズに合わせてModeFileを構築する必要がありますが、ここが最も問題が発生しやすい箇所でもあります。幻覚的な出力、自問自答、ループ出力、あるいは全く出力されないといった現象に遭遇することがあります。このような状況が生じる原因は、OllamaがモデルのModeFile内のTemplateに極めて敏感であることにあります。多くの場合、各モデルにはベンダーによってあらかじめ設定されたChat Templateが含まれていますが、モデルが暴走する根本的な原因は、ModeFileとモデルに組み込まれたChat Templateが一致せず、競合が発生することにあります。
同じモデルシリーズであってもバージョンが異なれば、組み込まれているチャットテンプレートには大きな違いがあります。Qwen3のModeFileをQwen3.5に適用すると、動作が不安定になることがあります。したがって、最も確実な方法は、モデル内のチャットテンプレートをエクスポートし、それに基づいて要件を満たすModeFileを構築することです。
テンプレートのエクスポート
通常、Ollama は Docker コンテナ 内で動作しますが、コンテナ内は最小限の構成(軽量化)であることが多いため、チャットテンプレートの抽出はホストマシン上で直接実行するのが最もスムーズです。
私は UNRAID を使用していますが、デフォルトでは Python 環境がないため、アプリストア(Community Applications)からインストールして対応しました。Synology や飞牛(FeiniuOS)などの NAS 環境でも同様にインストール可能です。
モデルディレクトリで、Pythonを使用して以下のコマンドを実行してください
python3 -c "
import os
import struct
def read_gguf_template(file_path):
try:
with open(file_path, 'rb') as f:
magic = f.read(4)
if magic != b'GGUF': return '【無効 GGUF】'
# 2MB メタデータのほぼすべてのケースを網羅
header_data = f.read(2 * 1024 * 1024)
key = b'tokenizer.chat_template'
pos = header_data.find(key)
if pos == -1: return '【テンプレートフィールドが見つかりません】'
# Jinjaテンプレートの特徴記号を特定する
start_jinja = header_data.find(b'{%', pos)
if start_jinja == -1: start_jinja = header_data.find(b'{{', pos)
if start_jinja != -1:
raw = header_data[start_jinja : start_jinja + 2000]
end_jinja = raw.rfind(b'%}')
# バイナリの残骸をデコードして削除する
res = raw[:end_jinja + 2].decode('utf-8', 'ignore') if end_jinja != -1 else raw.decode('utf-8', 'ignore')
return res.strip()
return '【キーワードは見つかったが、開始位置を特定できない】'
except Exception as e:
return f'【読み取りエラー: {e}】'
files = sorted([f for f in os.listdir('.') if f.endswith('.gguf')])
if not files:
print('Error: 現在のディレクトリには .gguf ファイルが見つかりませんでした')
else:
for file in files:
print('\n' + '★' * 40)
print(f'モデルファイル: {file}')
print('--- 元のテンプレートの内容 ---')
print(read_gguf_template(file))
print('★' * 40)
"その後、モデルの目の下には同じ名前のものが表示されます
追伸:私は主にQ4_K_Mモデルを使用しており、圧縮率は適度です。
混乱の原因
例としてQwen3.5を挙げると:
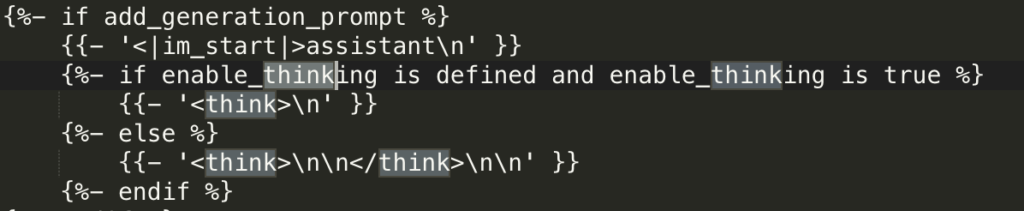
テンプレートには <think>\n\n</think>Modelfile が定義されていない PARAMETER stop "<|im_end|>"
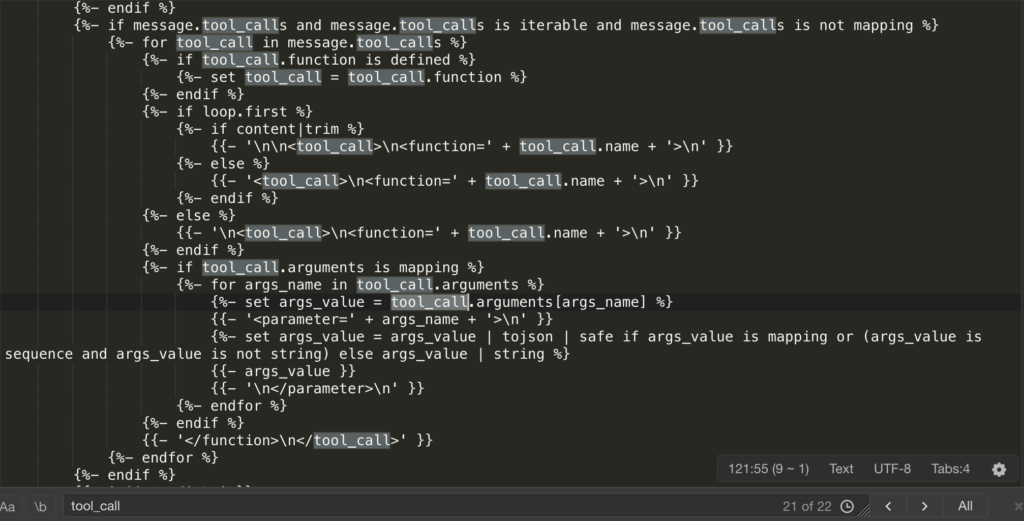
現在のエージェントやスキルブームに対応するため、Qwen3.5には多数の <tool_call>、<function=...> および <parameter=...>が大量に追加されました。Ollamaから渡されるシステムプロンプト(System Prompt)が不完全な場合、モデルはツールを呼び出す必要があると「誤認」してしまいます。呼び出すべきツールがないと判明すると、テンプレート形式に従って関数名や引数を無作為に作り始め、「無意味な内容」を生成してしまいます。
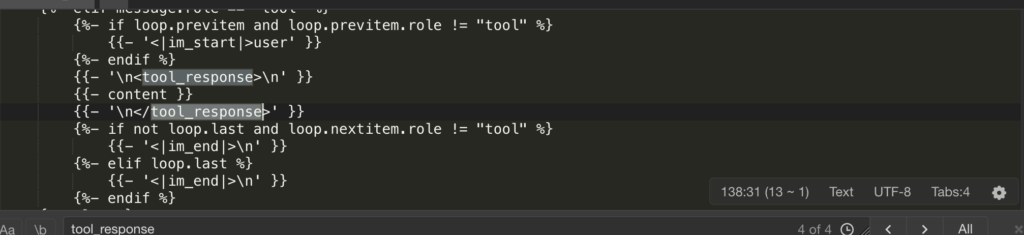
テンプレートにはロジックが含まれています:{% if message.role == "tool" %}<|im_start|>user\n<tool_response>。Ollamaのデフォルトロジックでは、user と assistant は交互に現れます。一方、Qwen3.5はツールの返却形式に合わせるため、 tool の返り値を user ロールにラップしています。もし Ollama の Modelfile が単にロールを定義しているだけの場合、コンテキストのロールのずれが生じます。モデルは突然自分がユーザーであると認識し、「ループ」という錯覚を引き起こします。
Modeflieのカスタマイズ
構造モデルに組み込まれているテンプレートを使えば、Modeflieの作成は格段に簡単になります。モデルに組み込まれているChat Templateに基づいて、私はThinkとAgentという2つのModeflieを作成しました。
| 特徴 | Think モード(思考型) | エージェント型(実行型) |
| 温度 (Temp) | 0.6~0.8(創造性を維持) | 0.1~0.4(安定性を重視) |
| コンテキスト (Ctx) | 32768(長文分析) | 8192 ~ 16384(必要十分な容量であれば) |
| 中核となるロジック | 誘導式 <think> 起動 | ツール呼び出しの強制制約 |
| ストップワード | 一般的なロールタグ | 追加 </think> 切り取り |
Thinkは、スケジューリング、計画立案、計画の細分化、既存文書の学習などに使用されます。<think>を使用することでモデルに自己検証を行わせ、生成の品質を向上させます。選択したベースモデルが思考モードに対応していない場合、Modeflieに<think>を追加してThinkモデルに変換しようとしないでください。そうすると、生成結果が文字化けしてしまいます。
FROM ./Qwen3.5-4B-Q4_K_M.gguf
TEMPLATE """<|im_start|>system
{{ .System }}<|im_end|>
{{ range .Messages }}<|im_start|>{{ .Role }}
{{ .Content }}<|im_end|>
{{ end }}<|im_start|>assistant
<think>
"""
SYSTEM """You are an expert reasoning assistant. For every problem, think carefully and thoroughly before answering. Show your reasoning process inside <think> tags, then provide a clear, well-structured final answer after </think>."""
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|endoftext|>"
PARAMETER num_gpu 99
PARAMETER num_ctx 32768
PARAMETER temperature 0.6
PARAMETER top_p 0.95
PARAMETER top_k 40
PARAMETER repeat_penalty 1.1
PARAMETER num_predict 8192Agentは、各種ツールを呼び出し、リアルタイムでコンテンツを迅速に生成する役割を担います。Agentのmodefileでは、ツールの呼び出し、実行、および出力のルールが厳格に規定されています。実行中にモデルに思考をさせると、実行効率が低下するだけでなく、思考によって実行プロセスにずれが生じる恐れがあります。したがって、実行中に</think>で思考プロセスを終了させるほか、PARAMETER stop “</think>”パラメータを使用して思考を強制終了させることも可能です。
FROM ./Qwen3.5-4B-Q4_K_M.gguf
TEMPLATE """<|im_start|>system
{{ .System }}<|im_end|>
{{ range .Messages }}<|im_start|>{{ .Role }}
{{ .Content }}<|im_end|>
{{ end }}<|im_start|>assistant
<think>
</think>
"""
SYSTEM """You are a precise, execution-focused AI assistant operating as an agent backend.
## Tool Usage
- Call tools proactively when external data, retrieval, or computation is needed.
- Return tool calls as valid JSON strictly following the provided schema.
- Include all required fields. Never omit or fabricate parameter values.
- If a required parameter is missing or ambiguous, ask for clarification before calling.
- After receiving tool results, synthesize and respond — do not re-expose raw tool output.
## Task Handling
- RAG / Retrieval: Query precisely. Summarize retrieved content faithfully without hallucination.
- Data processing: Apply operations step by step. Validate output structure before responding.
- Multi-step planning: Break complex tasks into subtasks. Track progress and adjust plan if a step fails.
## Output Rules
- Structured tasks → use JSON or markdown tables as appropriate.
- Free-form tasks → plain concise prose, no filler.
- Never guess. Never pad. If uncertain, say so explicitly."""
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|endoftext|>"
PARAMETER num_gpu 99
PARAMETER num_ctx 16384
PARAMETER temperature 0.6
PARAMETER top_p 0.9
PARAMETER top_k 40
PARAMETER repeat_penalty 1.1
PARAMETER num_predict 2048「PARAMETER」のパラメータ設定は、ご自身の環境や要件に合わせて調整可能です。
チームワーク、1+1>2
このModelfileに対する「脳外科手術」のような作業を通じて、私たちは実際には単一のモデルを基盤として、全く異なる2つの「人格」を生み出したのです。これこそが、ローカル大規模モデルの「影分身の術」なのです:
- Thinker: 長文の分析や論理の精査を担当し、
<think>タグ内で複雑な思考の流れを構築する。 - Executor: 面倒で骨の折れる作業を担当し、JSON出力を厳格に実行する。余計なことは一切言わず、結果だけを提供する。
このような「同源の分身」という協業のロジックは、異なるブランドや規模のモデルを組み合わせる場合と比べ、次元を落とすような圧倒的な優位性を持っている:
- コミュニケーションのズレがゼロ: これらは同一のトークナイザー(Tokenizer)と基盤ロジックを共有しているため、分身Aが意図した内容を分身Bが瞬時に正確に理解でき、モデル間での呼び出し時に生じるプロトコルの整合コストを大幅に低減します。
- 究極の省スペース: いくつキャラクターを作成しても、ハードディスクに占有する容量は常に1つ分のみ
Qwen3.5-4B-Q4_K_M.gguf容量しか使用しません。 - NASの性能が飛躍的に向上:リソースが限られたNAS環境であっても、「特化型チューニング」を施した小型モデルを用いることで、特定のタスクにおける安定性と応答速度は、肥大化した汎用大型モデルをも凌駕する可能性があります。
エージェントのプライベート化における究極の閉ループ
エージェントのプライベート化が進む中、Ollamaはもはや単なるモデルローダーではなく、むしろ「人材市場」のような存在となっています。
Modelfileによるきめ細かな制御により、『NARUTO -ナルト-』のように、任務の難易度に応じて無数の「分身」を召喚することができます。ある分身はセキュリティチェックを担当し、ある分身はコード監査を担当し、ある分身はデータクレンジングを担当します……。それらは一つの脳(Weights)を共有しながらも、それぞれが異なる役割を果たします。
あなたのローカルAIが、あなたの指示に応じて「熟考」と「迅速な実行」をシームレスに切り替えられるようになれば、それはもはや単なるチャットボットではなく、呼び出せば即座に応じ、絶対的な忠誠心を持ち、あなたの本質を理解するAI特殊部隊となるのです。
脳外科手術が完了しました。さあ、Ollamaを再起動して、分身の合体攻撃の力を体感しましょう!








