Agent私有化的时代,Ollama是非常适合的AI模型运行基座,根据需求不同,交错加载不同的模型,以实现Agent的行为目的。不过ollama官方library的模型普遍占用空间比较大,而且不能自定义。相比较而言,从huggingface拉取是一个很好的选择。

恰好最近Qwen和Gemma都更新了新模型,号称对Agent和Skill友好,赶紧试一试。然而明明拉取了最强的 Qwen3.5,跑起来却像是个自言自语的疯子?这大概率不是模型智商问题,而是 Ollama Modelfile 缺少一场‘脑外科手术’。

huggingface拉取的模型,需要我们根据自己需求构建ModeFile,但这也往往是出现问题最多的地方,我们会遇到幻觉输出、自问自答,循环输出或者根本就不输出。这种情况的原因就是Ollama对于模型ModeFile中的Template极为敏感。大部分情况下各个模型中都有发布厂商预制的Chat Template,而出现模型暴走的根本原因是ModeFile与模型内置的Chat Template不一致而发生了冲突。
即使是同一个模型系列不同版本,内置的Chat Template差异也是很大的,Qwen3的ModeFile放到Qwen3.5就会出现暴走。所以最稳妥的方式就是导出模型内的Chat Template,并根据它去构建满足我们需求的ModeFile。
导出模版
通常Ollama是运行在容器中的,但是容器的环境通往往是精简的,所以要想提取Chat Template,最好的方式是在宿主机下直接执行。我是在UNRAID中运行的,默认是没有Python环境的,可以通过应用市场安装,同样的在群晖和飞牛中也可以安装。
在模型目录以Python的方式运行以下命令即可
python3 -c "
import os
import struct
def read_gguf_template(file_path):
try:
with open(file_path, 'rb') as f:
magic = f.read(4)
if magic != b'GGUF': return '【无效 GGUF】'
# 2MB 覆盖绝大多数元数据情况
header_data = f.read(2 * 1024 * 1024)
key = b'tokenizer.chat_template'
pos = header_data.find(key)
if pos == -1: return '【未找到模板字段】'
# 定位 Jinja 模板特征符号
start_jinja = header_data.find(b'{%', pos)
if start_jinja == -1: start_jinja = header_data.find(b'{{', pos)
if start_jinja != -1:
raw = header_data[start_jinja : start_jinja + 2000]
end_jinja = raw.rfind(b'%}')
# 解码并清理可能存在的二进制残留
res = raw[:end_jinja + 2].decode('utf-8', 'ignore') if end_jinja != -1 else raw.decode('utf-8', 'ignore')
return res.strip()
return '【找到关键字但无法定位起始点】'
except Exception as e:
return f'【读取出错: {e}】'
files = sorted([f for f in os.listdir('.') if f.endswith('.gguf')])
if not files:
print('Error: 当前目录下没找到任何 .gguf 文件')
else:
for file in files:
print('\n' + '★' * 40)
print(f'模型文件: {file}')
print('--- 原始模板内容 ---')
print(read_gguf_template(file))
print('★' * 40)
"之后在模型的目下就可以看到同名的
PS:我大部分使用Q4_K_M的模型,压缩比比较适中。
混乱的原因
以Qwen3.5为例:
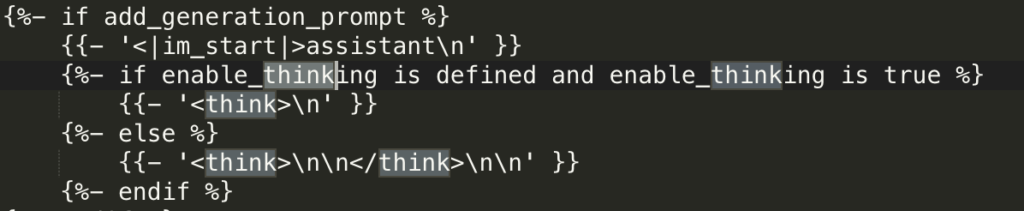
模板中包含了 <think>\n\n</think>结构,如果Ollama的Modelfile 没有定义 PARAMETER stop "<|im_end|>" 或者没有处理好思维链标签,模型就会进入循环思考。
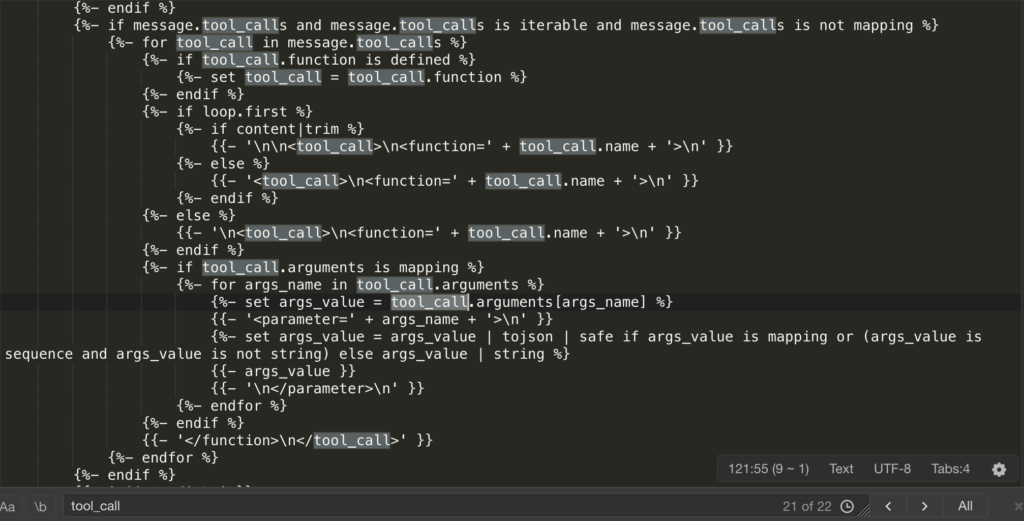
为了适应现在的Agent和Skill热潮,Qwen3.5加入了大量的 <tool_call>、<function=...> 和 <parameter=...>,如果Ollama 传入的系统提示(System Prompt)不完整,模型会“误以为”它需要调用工具。当它发现没有工具可调时,它会按照模板格式开始胡乱编造函数名和参数,产生“无意义内容”。
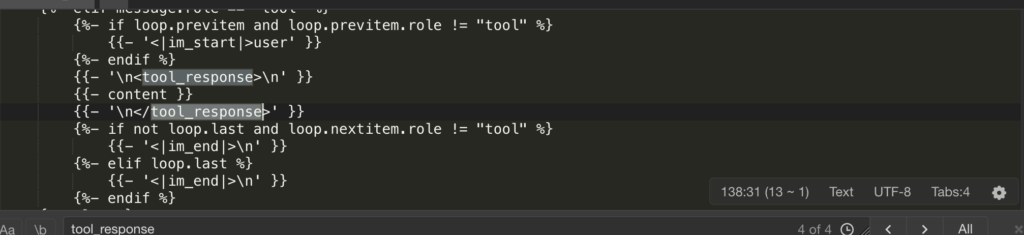
模板里有逻辑:{% if message.role == "tool" %} 后面会接 <|im_start|>user\n<tool_response>。在 Ollama 的默认逻辑里,user 和 assistant 是交替出现的。而Qwen3.5为了兼容工具返回,把 tool 的返回内容包装进了 user 角色里。如果 Ollama 的 Modelfile 只是简单定义了角色,会导致上下文角色错位。模型会突然觉得自己是用户,造成“循环”假象。
自定义Modeflie
结构模型内置的模版,构建Modeflie就简单多了。根据模型中内置的Chat Template,我构建了Think和Agent两个Modeflie。
| 特性 | Think 模式 (思考型) | Agent 模式 (执行型) |
| 温度 (Temp) | 0.6 – 0.8 (保留创造力) | 0.1 – 0.4 (追求稳定性) |
| 上下文 (Ctx) | 32768 (长文本分析) | 8192 – 16384 (够用即可) |
| 核心逻辑 | 诱导式 <think> 开启 | 强制工具调用约束 |
| 停止词 | 常规角色标签 | 增加 </think> 截断 |
Think,用来排程、规划、分解计划、学习既有文件等。通过<think>让模型自我验证,提高生成质量。如果选择的基础模型不支持思考模式,则不要尝试在Modeflie中加入<think>让它转变为Think模型,这回导致生成乱码。
FROM ./Qwen3.5-4B-Q4_K_M.gguf
TEMPLATE """<|im_start|>system
{{ .System }}<|im_end|>
{{ range .Messages }}<|im_start|>{{ .Role }}
{{ .Content }}<|im_end|>
{{ end }}<|im_start|>assistant
<think>
"""
SYSTEM """You are an expert reasoning assistant. For every problem, think carefully and thoroughly before answering. Show your reasoning process inside <think> tags, then provide a clear, well-structured final answer after </think>."""
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|endoftext|>"
PARAMETER num_gpu 99
PARAMETER num_ctx 32768
PARAMETER temperature 0.6
PARAMETER top_p 0.95
PARAMETER top_k 40
PARAMETER repeat_penalty 1.1
PARAMETER num_predict 8192Agent,则是调用各种工具,以及快速生成即时内容的。Agent的modefile中严格限制了调用工具、执行和输出的规则。如果在执行的过程中,让模型思考,会导致降低执行效率,而且思考还会使执行的过程发生偏移。所以在执行中通过</think>终结思考流程,同样也有通过PARAMETER stop "</think>"参数强制终止思考。
FROM ./Qwen3.5-4B-Q4_K_M.gguf
TEMPLATE """<|im_start|>system
{{ .System }}<|im_end|>
{{ range .Messages }}<|im_start|>{{ .Role }}
{{ .Content }}<|im_end|>
{{ end }}<|im_start|>assistant
<think>
</think>
"""
SYSTEM """You are a precise, execution-focused AI assistant operating as an agent backend.
## Tool Usage
- Call tools proactively when external data, retrieval, or computation is needed.
- Return tool calls as valid JSON strictly following the provided schema.
- Include all required fields. Never omit or fabricate parameter values.
- If a required parameter is missing or ambiguous, ask for clarification before calling.
- After receiving tool results, synthesize and respond — do not re-expose raw tool output.
## Task Handling
- RAG / Retrieval: Query precisely. Summarize retrieved content faithfully without hallucination.
- Data processing: Apply operations step by step. Validate output structure before responding.
- Multi-step planning: Break complex tasks into subtasks. Track progress and adjust plan if a step fails.
## Output Rules
- Structured tasks → use JSON or markdown tables as appropriate.
- Free-form tasks → plain concise prose, no filler.
- Never guess. Never pad. If uncertain, say so explicitly."""
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|endoftext|>"
PARAMETER num_gpu 99
PARAMETER num_ctx 16384
PARAMETER temperature 0.6
PARAMETER top_p 0.9
PARAMETER top_k 40
PARAMETER repeat_penalty 1.1
PARAMETER num_predict 2048PARAMETER 参数部分则可以根据自己的设备环境和需求自己调整。
团队作战,1+1>2
通过这种 Modelfile 的“脑外科手术”,我们实际上是在单体模型的基础上,分化出了两个截然不同的“人格”。这就是本地大模型的影分身之术:
- Thinker: 负责消化长文档、推敲逻辑,在
<think>标签内完成复杂的思维链路。 - Executor: 负责干脏活累活,严格执行 JSON 输出,绝不废话,只给结果。
这种“同源分身”的合作逻辑,相比混搭不同品牌、不同规模的模型,具有降维打击般的优势:
- 零沟通偏差: 因为它们共享同一套词表(Tokenizer)和底层逻辑,分身 A 规划的意图,分身 B 能精准“秒懂”,极大降低了跨模型调用时的协议对齐成本。
- 极致省空间: 无论你分出多少个角色,硬盘上始终只占用一份
Qwen3.5-4B-Q4_K_M.gguf的体积。 - NAS 性能飞跃: 即便是在资源有限的 NAS 环境下,通过“专精调优”的小参数模型,在特定任务上的稳定性和响应速度,甚至能超越那些臃肿的通用大模型。
Agent 私有化的终极闭环
在 Agent 私有化的浪潮中,Ollama 不再仅仅是一个模型加载器,它更像是一个“人才市场”。
通过 Modelfile 的精细控制,你可以像NARUTO -ナルト-那样,根据任务难度召唤出无数个“分身”:一个负责安全审查,一个负责代码审计,一个负责数据清洗……它们共用一个大脑(Weights),却各司其职。
当你的本地 AI 能够根据你的指令,自动在“深思熟虑”与“雷厉风行”之间无缝切换时,你拥有的就不再是一个只会聊天的机器人,而是一支召之即来、绝对忠诚且懂你底层的 AI 特种部队。
脑外科手术完成。现在,重启 Ollama,感受分身合击的力量吧!








